Backups on ECS/EFS to S3 using Duplicity
Idealstack • January 29, 2018
configurationUPDATE: use AWS Backup instead
AWS have released a new solution, AWS Backup, which is probably a better choice for most people looking to backup EFS. We've written an article on how to set it up. We'll keep this doc here though as it might still be useful to those for whom the AWS solution doesn't work well.
Backups on ECS/EFS using duplicity
At Idealstack we use EFS a lot as a persistent data store for docker containers on ECS, inspired by this. But how do you deal with backups? We don’t really want to have to maintain scripts on an EC2 instance - our EC2 instances are unmodified copies of the Amazon ECS Optimised AMI that are created and destroyed all the time and we treat them as cattle, not pets
AWS’s recomended solution is backup from EFS to another EFS using bunch of lambda functions that create EC2 instances to do a backup, but we don’t like that - EFS is the most expensive storage product that AWS offers, and we don’t feel it’s suited to long-term archives like backups (on the other hand, EFS to EFS backup will give faster restores than the solution we offer here - there's no reason not to do both if you need both quick restores and long term retention).
Our favoured backup system is duplicity. It can backup to S3 (or almost anything else). We then automatically migrate backups to Glacier after 3 months to provide super-long-term retention of everything. So it makes sense to use a docker container running duplicity to do backups. We feel this is a more elegant solution for ECS users than a lot of lambda functions and EC2 instances, and it’s probably cheaper to, using as it does resources you already have running.
Note that this solution will work perfectly for users of the idealstack hosting system (it's what we use it for) but it should also work fine for anyone else running ECS & EFS together - just update the paths we give here with those you use.
Setting up backups
Create an S3 bucket to store your backups. Use the same region as your ECS cluster lives in. Otherwise you can accept all the defaults.
Create an IAM policy allowing access to this bucket
Go to IAM and navigate to Roles in the IAM menu

Click “Create Policy” at the top of the screen
On the IAM policy editor, select JSON and paste in the following: https://gist.github.com/jonathonsim/581dca42a0779a2416aaf1936e4679fd
- Update the s3 bucket name to match yours
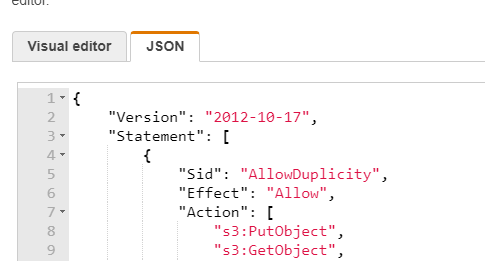
- Update the s3 bucket name to match yours
Click Review policy

Give the policy a name (eg S3BackupAccessForDuplicity)
Attach this policy to the instance role for ECS. Note that in theory we should use a task role for this, but at this time that doesn’t appear to work in duplicity
In ECS - click on your cluster, go to the ECS Instances tab

Click your EC2 Instance
Under the Description of the instance click the IAM Role
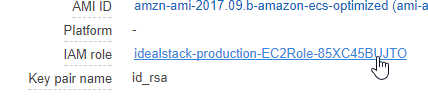
Attach the policy you just created to this role :
Back In ECS create a task definition:
- Give it a sensible name
Scroll down to Volumes (skip the other settings for now, we’ll come back to them) and click Add Volume
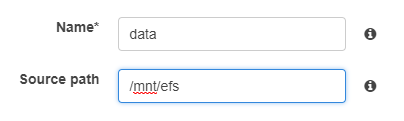
Add a volume for the data you are backing up
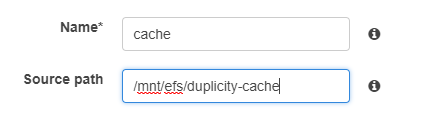
Add a volume for the duplicity cache, somewhere persistent (ie on the EFS)
Under Container Definitions: click “Add Container”
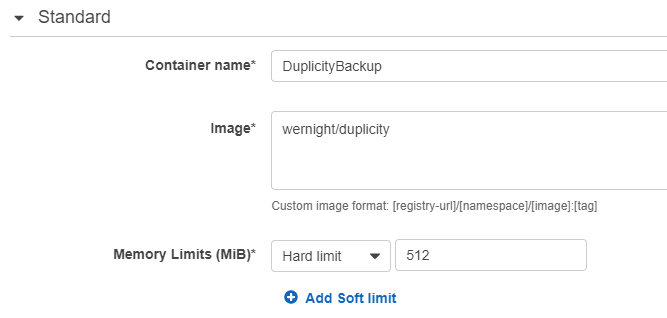
Give the container a name, eg DuplicityBackup
For the image, we’re going to use https://hub.docker.com/r/wernight/duplicity/, so enter “wernight/duplicity”
For memory limit - choose a hard limit of 512MB (you don’t want backups using up all your RAM)
This section should look like this now:
Under environment, enter the command : update to match your bucket. Also think about what the ‘full-if-older-than’ option should be - it depends how much your data changes:
/bin/sh, -c, duplicity --exclude=/data/duplicity-cache --exclude=/data/duplicity-restore --full-if-older-than=3M --s3-use-new-style --asynchronous-upload /data s3+http://my-example-bucket/backups; duplicity cleanup --s3-use-new-style --force s3+http://my-example-bucket/backups

Setup an environment varialbe with your passphrase. You can generate one here: https://passwordsgenerator.net/
- Create an env variable called PASSPHRASE and set your passphrase

- Create an env variable called PASSPHRASE and set your passphrase
The only other settings you need to setup are under Storage:
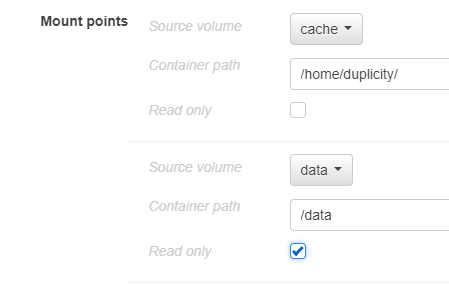
Add a mount point for the cache, on /home/duplicity
Add a mount point for the data on /data. You can check ‘read only’ on this:
Choose the log driver of your preference, in production we use awslogs, but we’ll use Syslog for this example as it’s easy : log messages will then appear in the syslog (/var/log/messages on Amazon Linux)

Under security - choose the user to run the backup as. Note that it’s great if your file permissions are such that an unpriviliged user can be used here, but that’s not always practical and you may need to choose ‘root’
Leave all the other settings and click Update
Now click Create on the task definition
Now let’s do a backup to see if it works. Under Actions, run the task:
- It should take a while, depending how much data you have. You’ll see items start to appear in your s3 bucket. If it doesn’t work, check the syslog on the instance (or wherever else you configured your logs to go)
Scheduling your backup to run every night
You’ll want to schedule your backup to run every night. This is easy to do as a scheduled task in ECS
In ECS, click on your cluster and choose Scheduled Tasks and click Create
Give your schedule rule a name
Choose “Cron Expression” as the rule type
Enter an AWS Schedule expression for whent to run the backup. As an example, this will run the backup at 2am every morning
cron(0 2 * * ? *)

Under Schedule Targets - give you target an ID, and select your task definition that you created above

Accept all the other defaults and click Create
Things will crunch for a moment before telling you that your scheduled task has been created
Restoring your backups
To restore backups, you can run duplicity on any host, but it can be convenient to create an ECS Task definition for it - then just run that in the ECS console or CLI to restore. Doing this is very similar to the steps above:
Create a task definition as above and give it a name (eg DuplicityRestore)
Add the location you want to restore to as a volume. We restore onto a directory on the EFS so that there’s space, but use a subdirectory as we don’t want to be nuking our files with restores:
Add a volume for the restore directory and call it data. Here we use /mnt/efs/duplicity-restore
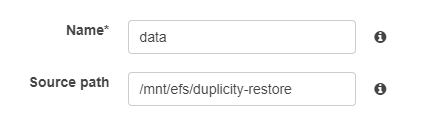
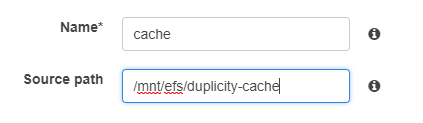
Add a volume for the duplicity cache, identical to the one you used in the backup task
Add the container
Use the same image wernight/duplicity
For the command use this, replacing your bucket name:
duplicity, restore, --s3-use-new-style, s3+http://my-example-bucket/backups, /dataUnder Env Variables, create one called PASSPHRASE and paste in the same passphrase that you used in the backup task
Under volumes : select the data volume and mount it to /data, select the cache volume and mount it to /home/duplicity
Choose the user (eg ‘root’)
Save the task definition
Run the task. Hopefully you should see your data restored into the target directory you chose
What if I want to restore from further back?
When running the task, under Advanced Options & Container Overrides, modify the command and add --time=3D (or whatever date specification you want)
What else can you do next?
Cleaning up and archiving the old backups to Glacier
We actually never delete backups. If you do want to do that, you can make duplicity do it - add something like duplicity remove-older-than 6M --force s3+http://example-bucket/backups
We prefer to use a lifecycle rule, that migrates backups older than 100 months to glacier (make sure this time is longer than the time between full backups you've given duplicity, otherwise you can't restore anything without digging into glacier). So far we keep them there forever, but we might further expire
Monitoring your backups
I’m a firm believer that you need to monitor your backups automatically. When they die you want to know quickly, not when you next go to restore a backup and they don’t work. One way to do this (certainly not a catch-all) is to at least check that something is being written to your s3 bucket ever 24 hours. For this you need to enable request metrics in S3 (which costs extra), then setup an alarm when the sum of those over 24 hours is zero
We've create a metrics filter in cloudwatch logs looking for the phrase "error". The alarm on this sends us an email when there's an error in duplicity. What more could we do? Parsing the output of duplicity collection-status is what we’ve done in the past, using nagios. We’ll probably try to hook something up using ECS & Cloudwatch to do this for us.
You’ll also want to schedule something in your calendar to remind you to do a test restore every so often.